Image Classification Pipeline
Image Classification
- Image Classification은 Computer Vision의 핵심 작업임.
- 사람의 뇌속의 시각 체계는 이미지를 입력 받았을 때, 개, 고양이, 트럭, 비행기 같은 것들의 레이블을 분류하는 시각적 인식능력을 타고 났음.

- 하지만 이러한 일들이 기계에게는 매우 어려움.
- 컴퓨터가 이미지를 볼때 숫자 그리드로 이미지를 표현함.
- 예시 사진의 고양이 이미지는 800 x 600 픽셀인데 각 픽셀은 3가지 숫자(RGB)로 표현됨.
- 컴퓨터에게 이미지는 큰 그리드 숫자일 뿐이고, 거기서 고양이라는 의미를 끌어내긴 어려움.
- 이 문제를 Semantic Gap(의미적 차이) 라고 하며 ‘고양이’ 라는 Label은 사람이 부여한 의미적 값임.
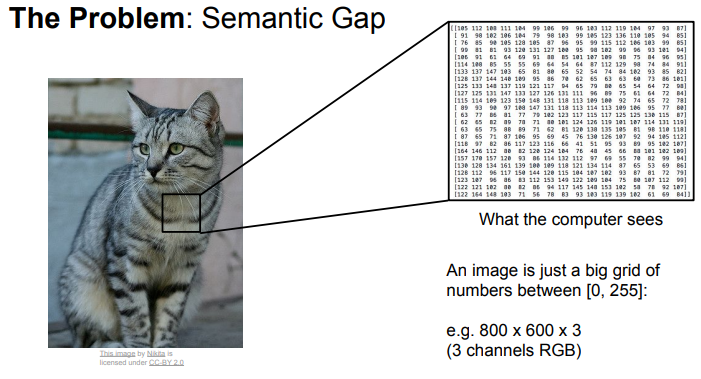
- 고양이를 찍는 카메라를 다른 방향으로 움직이면 그리드에서 모든 픽셀 값이 완전히 달라짐.
- 하지만 이미지가 고양이를 의미 하고 있는 것에는 변화가 없음.
- 알고리즘은 이런 변화에도 견고하게 고양이 임을 알 수 있어야함.
- 알고리즘은 카메라의 방향 뿐만 아니라, 조명에 의해 변하는 (너무 밝다 던지, 너무 어둡다던지) 조건에서도 동작 해야함.

- 물체가 형체를 바꾸는 경우도 고려해야함.
- 고양이는 다양한 포즈를 취할 수 있고 알고리즘은 이런 형태의 고양이도 분류 할 수 있어야 함.

- 이미지의 일부만 보여도 사람은 고양이라는 것을 알아차릴수 있지만 알고리즘에게는 매우 어려운 일임.
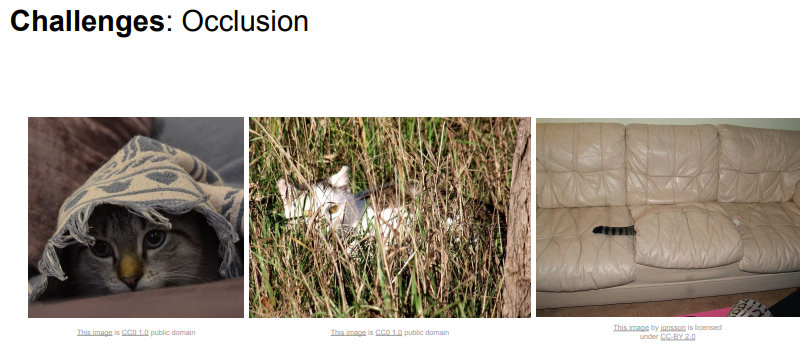
- 인식하려는 물체의 이미지와 배경이 유사한 경우에도 알고리즘은 구분할 수 있어야 함.

- 같은 고양이라도 다양한 모양과 크기와 색깔을 가지고 있음.
- 알고리즘은 Interclass Variation (클래스내 변화)에도 대응 할 수 있어야 함.

- 고양이는 다양한 모양과 크기, 색깔을 가지고 있고 알고리즘은 이런 모든 변화에 대응할 수 있어야함.

- Image Classification 을 위한 명확한 하드코딩 알고리즘 방법은 없음.
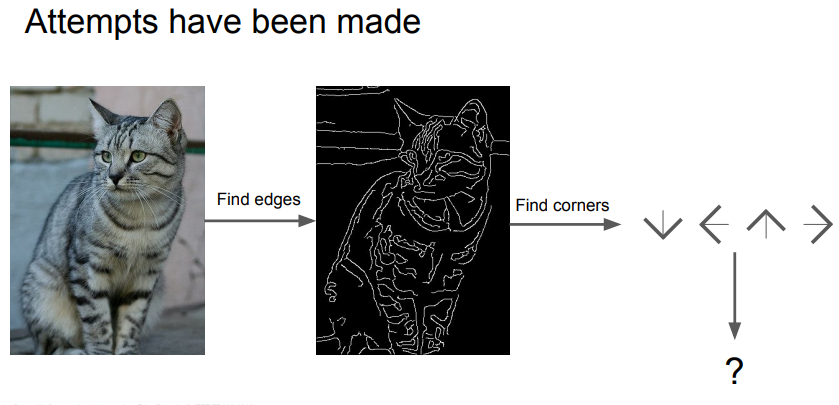
- 고양이가 눈, 귀, 코, 입이 있다는 것을 알고 Image의 Edge들을 계산해서 명시적 룰의 집합으로 고양이를 인식하려는 시도가 있었음.
- 하지만 잘 작동하지 않았고 확장 가능한 방법이 아니였음.

- Data-Driven Approach (데이터 중심 접근 방식) 은 사람이 지정하는 룰을 작성하여 Image Classification을 하기 보다는 수많은 Image는 모으고 다양한 카테고리로 나누어 모델을 학습시킴.
- Image를 받아서 고양이 인지 인식하는 하나의 함수에서 Image와 Label을 입력받아 모델을 출력하고 Image의 Label을 예측하는 두개의 함수로 구성이 변경됨.
- CS231n은 주로 Neural Network(신경망), CNN(합성곱 신경망), Deep learning에 관한 강좌인데 Data-Driven Approach가 Deep Learining보다 훨씬 더 일반적임.
Nearest Neighbors
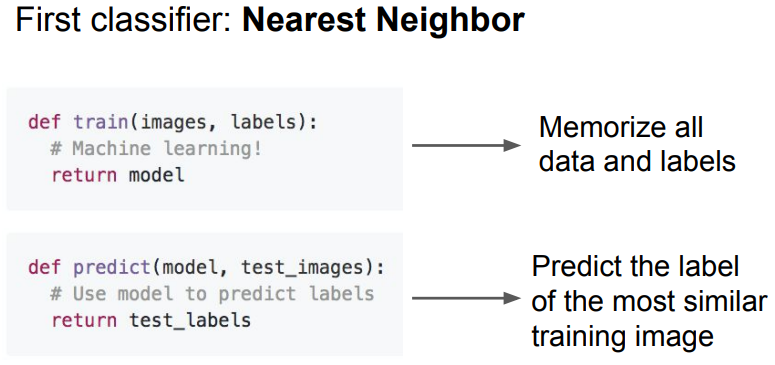
- Nearest Neighbors (최근접 이웃) 알고리즘은 학습된 Image와 가장 비슷한 레이블로 예측함.

- 머신러닝에서 흔하게 사용되는 CIFAR 10 이라는 Data Set을 살펴보면 10개의 Class (자동차, 비행기, 새, 고양이 등)에 해당하는 5만장의 학습 Image를 제공함.
- 또한 학습된 알고리즘을 Test 할 수 있는 1만장의 Image가 있음.

- CIFAR 10에 Nearest Neighbors 을 적용한 예를 살펴보면 왼쪽은 Label에 따라 카테고리로 나누어진 Image이고 오른쪽은 Test Image와 비슷한 Image를 Nearest Neighbors를 통해 보여줌.
- 두번째 행을 보면 Test Image가 개에 해당하지만 분류된 Image를 보면 사슴 혹은 말이 있음.
- 시각적으로 비슷해 보이는 (하얀부분이 가운데 있음) Image를 개와 같은 Image로 분류함.
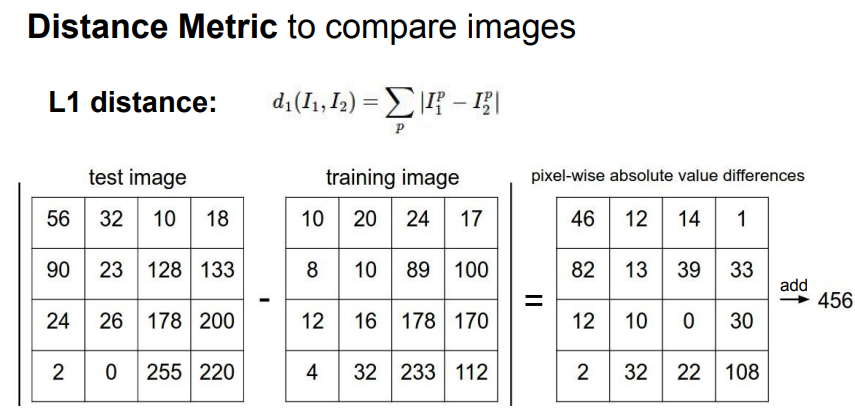
- 한 쌍의 Image가 주어지면 그것을 비교하는 방법은 많이 있음.
- 지난 강의에서 L1 Distance (Manhattan Distance)를 사용했고, 이는 Image 비교에 사용할 수 있는 쉬운 아이디어 임.

- Nearest Neighbor Classifier의 파이썬 코드를 살펴보면 Numpy가 제공하는 벡터화된 연산을 써서 짧고 간결함.

- Train Function을 보면 Train data를 저장 하기만 하면 되서 할 것이 별로 없음.
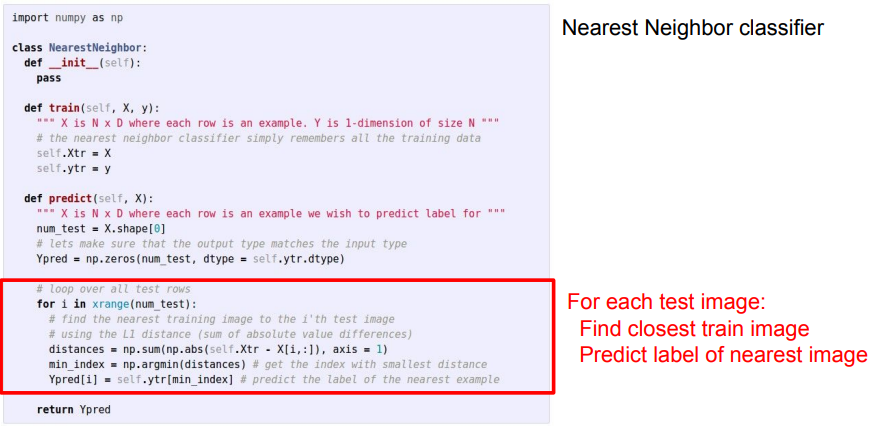
- Test 시에는 Test Image를 받아 Train data와 L1 Distance를 구하고 가장 비슷한 Image를 찾음.

- N개의 Train Data가 있을때 Train과 Test는 얼마나 빠를까?

- Train 은 Data만 입력하면 되니 상수임.
- 하지만 Test 시에는 데이터 셋의 N개의 예에 대해 Test Image와 비교해야함.
- Train이 빠르고 Test가 느린것은 실사용에서 좋지않음.
- 학습 모델의 배포를 고려 할 때 Train이 느리더라도 Test가 빨라야 좋은 알고리즘이라 할 수 있음.
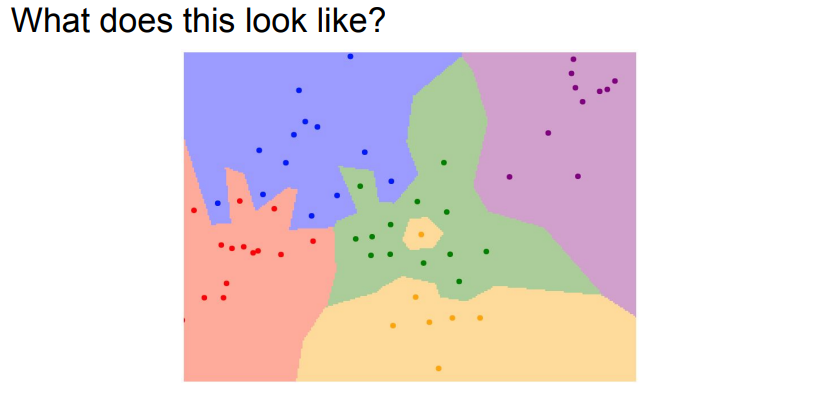
- Nearest Neighbor의 Decision Region(결정 영역)을 그려보면 각 색깔 별로 다른 카테고리를 나타내고 있음.
- 가운데 노란점이 있는 것을 보면 노이즈 이거나 비 논리적인 데이터일 것임.
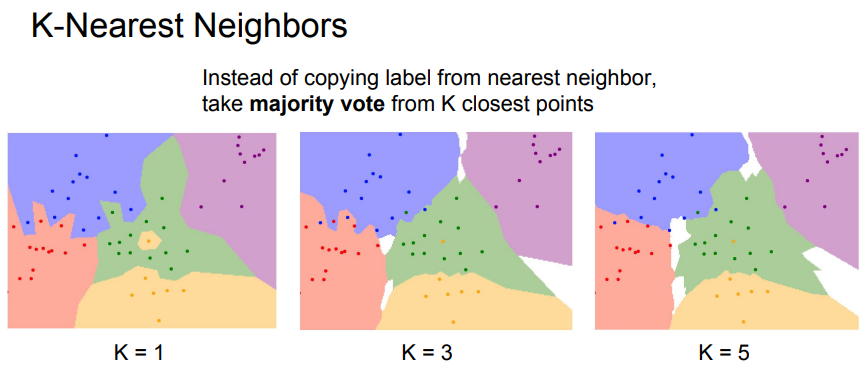
- K-Nearest Neighbors는 K개의 Nearest Neighbors를 찾아 투표를 함.
- K가 1인 Nearest Neighbors와 K가 3일때와 비교해 보면 K가 1일때 녹색안에 위치해서 주변을 노란색으로 만들었던 점이 K가 3일때는 주변 영역을 노란색으로 만들지 않음.
- K가 5일때는 3일때보다 Desision Boundary(결정경계)가 매우 부드러워지고 좋아짐.

- K-Nearest Neighbors 를 Image에 적용해 보면 성능이 좋지 않음.(정답:초록, 오답:빨강)
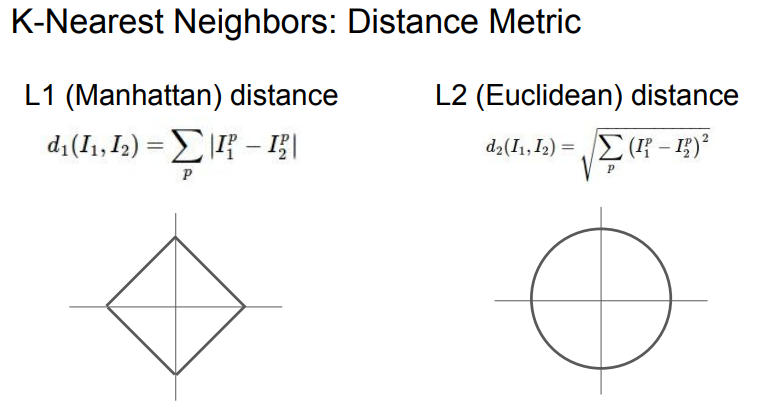
- K-Nearest Neighbors를 비교할 때 지금 까지는 L1 Distance를 언급했지만, L2 Distance도 많이 쓰임.
- L1 Distance는 좌표 시스템에 의존적이라 좌표 프레임을 회전하면 L1 점들간의 거리는 변화함.
- 하지만 L2 Distance에서는 좌표프레임 회전과 관계없이 거리가 같음.
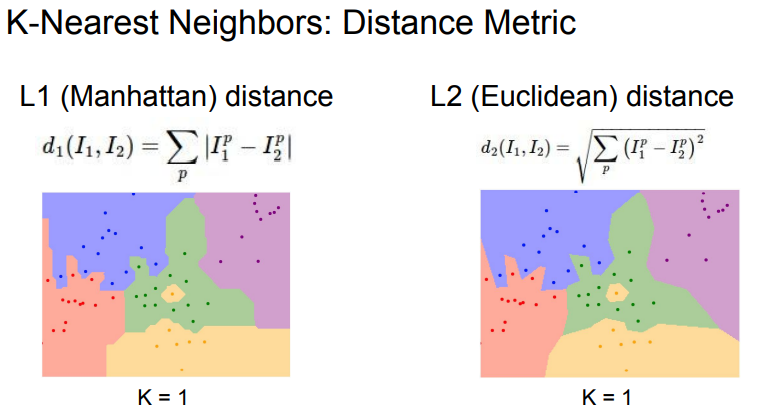
- L1 distance를 사용하면 Decision Boundary가 좌표축을 따라 그어짐.
- L2 distance의 경우에는 좌표축을 상관하지 않기에 Decision Boundary가 부드러움.
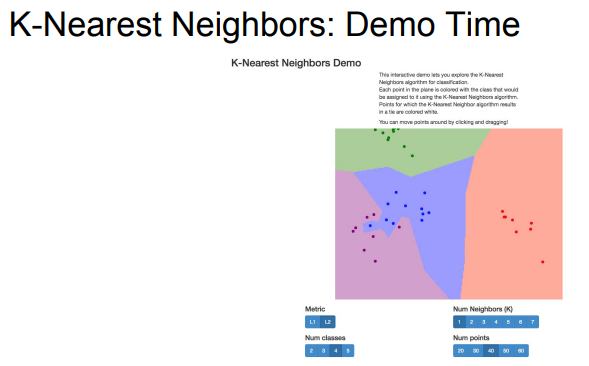
- K 값과 Distance에 따라 변화하는 경계를 확인해 볼 수 있는 웹 데모
K-Nearest Neighbors Demo

- 데이터에 따라 K 값과 Distance를 선택할 수 있고 이런 것들을 Hyperparameter라 부름.
- Hyperparameter는 데이터로 부터 학습 하는 값이 아니라 알고리즘에서 선택 해 주어야 하는 부분임.

- Hyperparameter를 선택하는 가장 간단한 방법은 여러 Hyperparameter 값을 시도해 보고 가장 최선의 Hyperparameter를 선택하는 것임.

- 모든 데이터에 대해서 최고의 정확도 혹은 성능을 내는 Hyperparameter를 선택 할 수 있음.
- 하지만 이건 좋은 아이디어가 아님.
- KNN(K-Nearest Neighbors)를 예로 K를 1로 설정하면 Train Dataset을 완벽하게 분류함.
- 궁극적으로 머신러닝 에서는 Train Dataset을 맞추는 것을 신경쓰지 않음.
- Train 단계에서 보지 못했던 Data에 대해 어떻게 동작하는 지가 중요함.
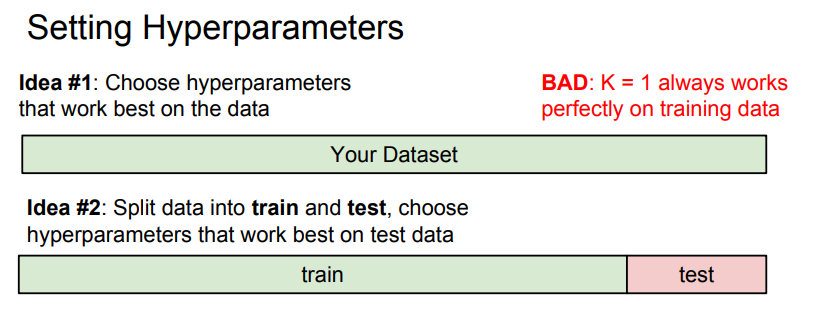
- 전체 Data Set을 Train Set과 Test Set으로 나누어 Train Set에 대해서 여러 Hyperparameter 값으로 학습을 시도하고, 그 다음 학습된 알고리즘을 Test Set에 적용하여 가장 잘 동작한 Hypterparameter를 선택함.
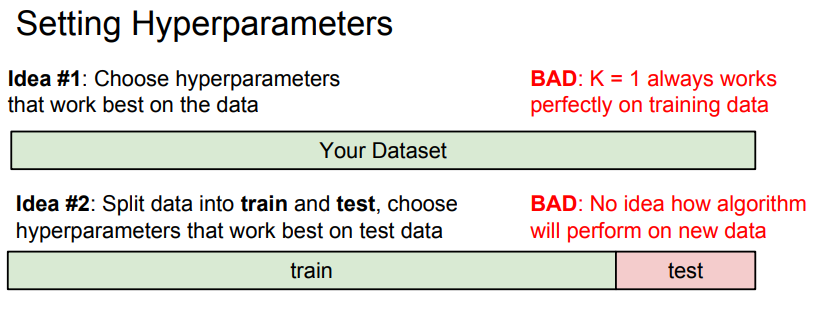
- Train/Test Set을 가지고 Hyperparameter를 선택하는 것이 합리적인 전략으로 보여지지만 새로운 데이터에 대해서 잘 작동하는지 알 수 없기 때문에 좋은 아이디어가 아님.
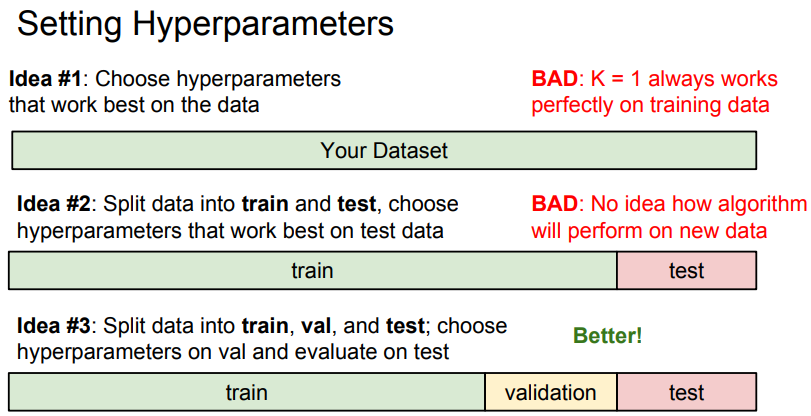
- 가장 좋은 방법은 3개의 Data Set으로 나누는 것임.
- Train/Validation/Test Data Set 으로 나누어 Train Set과 다양한 Hyperparameter로 알고리즘을 훈련하고 Validation Set으로 가장 성능이 좋은 Hyperparameter를 선택함.
- Validation Set에서 가장 성능이 좋았던 Classifier를 Test Set에서 실행해보고 이 결과가 알고리즘이 보지 않았던 Data에 대해 어떻게 동작할 지를 나타냄.
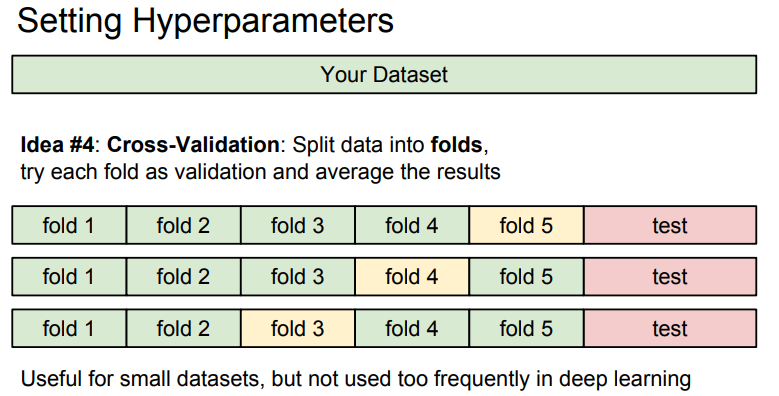
- Hyperparameter를 정하는 또 다른 전략은 Cross-Validataion(교차 검증)임.
- Cross-validation은 크기가 작은 Data Set에서 흔히 사용되고 Deep learning에서는 잘 사용되지 않음.
- Cross-validation은 여러개 폴드(folds)로 Data Set을 나누어 어떤 부분이 Validation Set이 될 지 고르는 것을 반복함.
- 이 예에서는 5 Fold Cross Validation을 사용했으며, 첫 4개의 Fold로 학습하고 성능을 5로 평가하고, 그 다음 1,2,3,5로 학습하고 Fold 4로 평가하고 모든 다른 Fold에 대해서도 반복함.
- Deep Learning에서는 Data Size가 클 때, Computing 비용이 비싸기 때문에 실제로 많이 쓰이지는 않음.
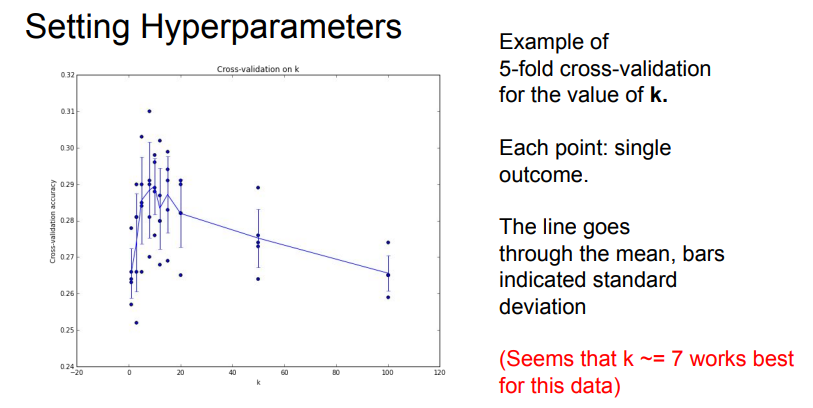
- Cross Validation을 하게되면 위와 같은 그래프를 얻게 됨. (X축: KNN의 K값, Y축: 정확도)
- 위 그래프에 따르면 해당 Data Set에서는 K=7일때, KNN이 가장 잘 작동함.

- KNN은 Image에 절대 사용하지 않음.
- KNN은 Test시 매우 느림. (Test 시 빨라야 실용성이 있음)
- L1, L2 Distance는 Image간 Distance를 측정하기에 좋은 방법이 아님.
- 예를 들어 위와 같은 여자 사진 Image가 여러 왜곡을 거쳤는데, 이 모든 사진이 같은 L2 Distance 값을 가지기 때문에 Classifier로써 좋은 결과를 가져 오지 못함.
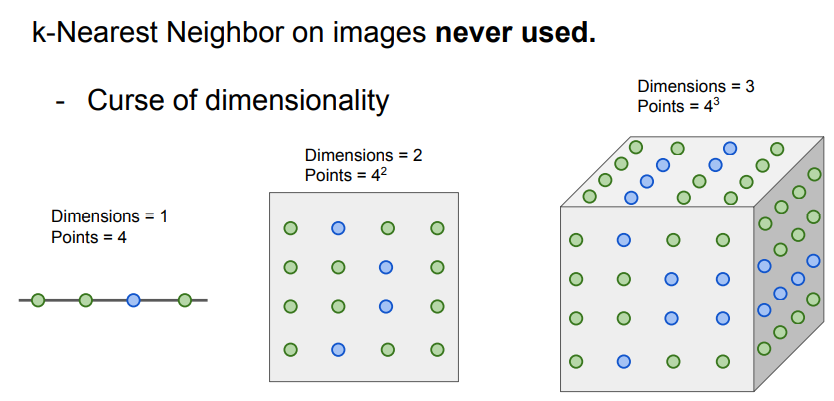
- KNN의 또다른 단점은 차원의 저주 (Curse of dimensionality)임.
- Distance를 계산할 때 차원이 늘어날수록 계산 해야하는 지점의 개수는 지수로 증가함.
Linear Classifiers

- KNN이 머신러닝 알고리즘의 좋은 특징을 가지고 있지만 Image에 대해서는 많이 쓰이지 않음.
- Linear Classifiers는 간단한 알고리즘 이지만 Neural Network를 구성하는 중요한 알고리즘임.
- Neural Network를 레고 블럭에 비유해보면 Neural Network는 다양한 구성 요소 들을 가지고 있을 것이고 CNN(Convolutional Neural Network)를 만들기위해 요소들을 서로 연결하게됨.
- Linear Classifiers는 보편적으로 사용되는 알고리즘임.
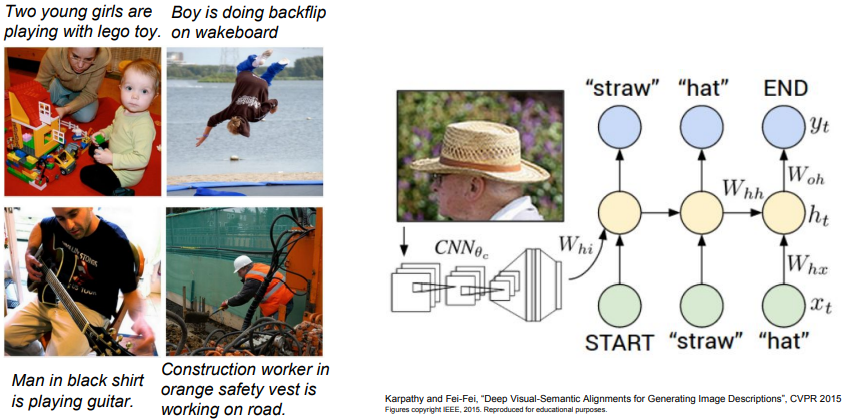
- Neural Network의 Module성을 잘 보여주는 예가 Image Captioning임.
- Image Captioning은 Image를 Input으로 받아서 Image를 해설하는 문장을 내보내게 구성 되어 있음.
- Image Captioning이 동작하는 방식은 Image를 인식하는 CNN이 있고, 언어에 대해 이해하는 RNN(Recurrent Neural Network)이 있어서 레고 블럭처럼 CNN, RNN을 연결하여 함께 학습을 시킴.
- CS231n에서는 해당사항을 계속 다룰 예정임.

- 다시 CIFAR 10으로 돌아와 보면, CIFAR 10은 5만개의 학습 Image가 있고 각 Image는 32 x 32 크기이며 3가지의 색으로 구성되어 있음. (RGB: Red, Green, Blue)
- Linear Classifier는 KNN과 조금 다른 방법으로 접근함.
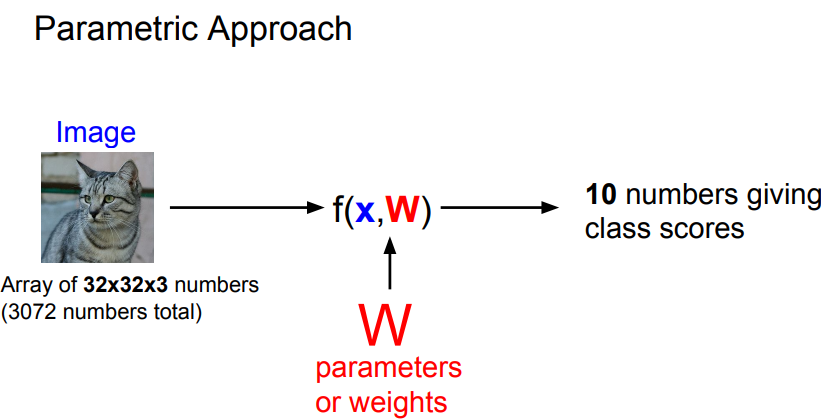
- Linear Classifier는 파라미터 모델이라고 부르는 것중 가장 간단함.
- 파라미터 모델은 2개의 Component를 가지고 있음.
- 데이터는 x로 표시하고 가중치(Weight)는 W로 표시함.
- x와 W의 함수를 f라 하고 f가 크면 고양이일 확률이 큼.
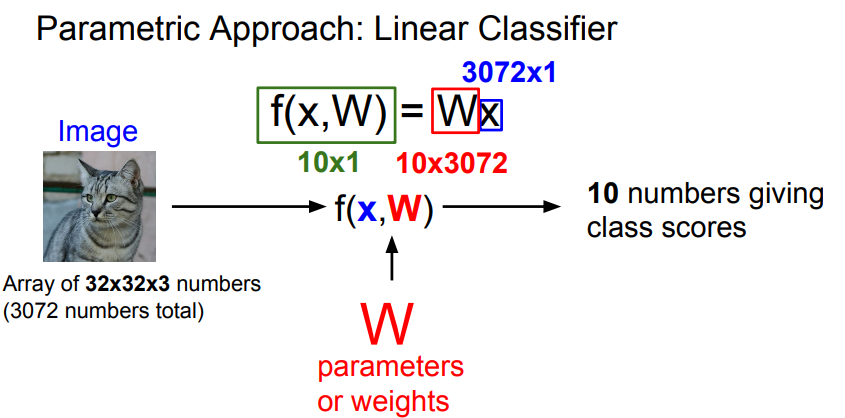
- W와 x를 조합하는 가장 간단한 예는 둘을 곱하는 것임.
- Image를 차수로 풀어보면, Input Image는 32 x 32 x 3이고 그값을 받아서 긴 열의 벡터로 만들고 3072개의 항목을 가지게됨.
- 3072개의 항목을 CIFAR10에 있는 10개의 카테고리에 해당하는 Class 점수로 만듦.
- 그러므로 W가 10 x 3072개가 되어야 함.
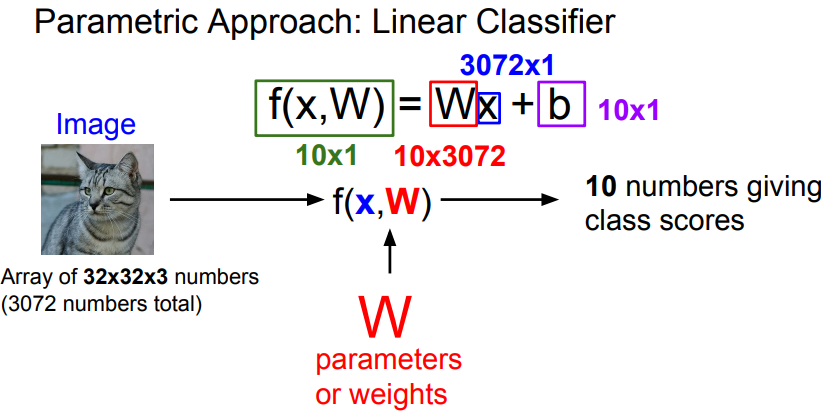
- 또한 각 함수 f는 Bias를 가짐.
- Bias를 상수 벡터로 10개의 원소로 되어 있으며 학습 데이터와는 상호작용하지 않고, 데이터와 무관한 선호도를 제공함.
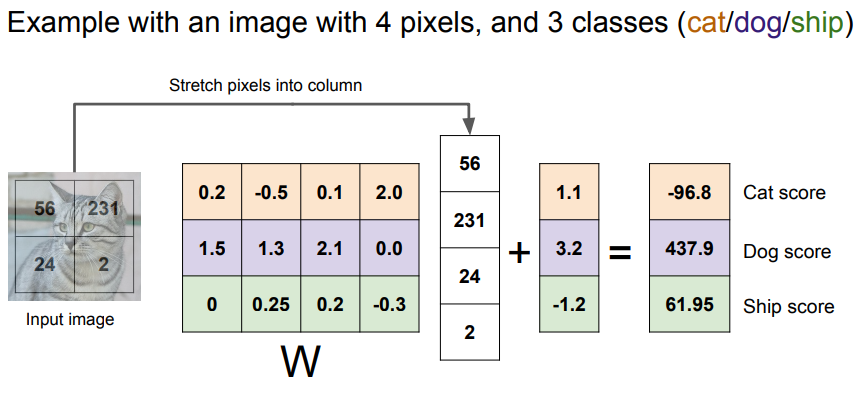
- 4개 픽셀 Image와 3개 Class(Cat, Dog, Ship)의 예를 보면, 왼쪽에는 단순한 2x2 Image가 있고 4개의 항목으로된 행 벡터가 하나로 늘여져 있음.
- Weight Matrix는 4 x 3 이됨. (4개의 픽셀, 3개의 Class)
- 또한 3개의 항목은 데이터에 독립적인 Bias 항을 가짐
- 고양이 점수는 Image 픽셀과 Matrix 행의 내적과 Bias의 합이됨. (0.2x56 + (-0.5)x231 + 0.1 x 24 + 2 x 2 + 1.1 = -96.8)

- CIFAR 10에서 Linear Classifier로 학습시킨 10개 카테고리를 시각화 해보면, 각 이미지들은 흐릿하게 각각 물체 특징을 보이는 것처럼 보이지만 자세히 보면 말이 머리가 두개인것처럼 보이는 조금 이상한 부분들이 있음.
- Linear classifier는 Class당 하나의 Templete밖에 허용하지 않지만 Neural Network와 같은 복잡한 모델이라면 조금 더 높은 정확도를 볼 수 있을 것.
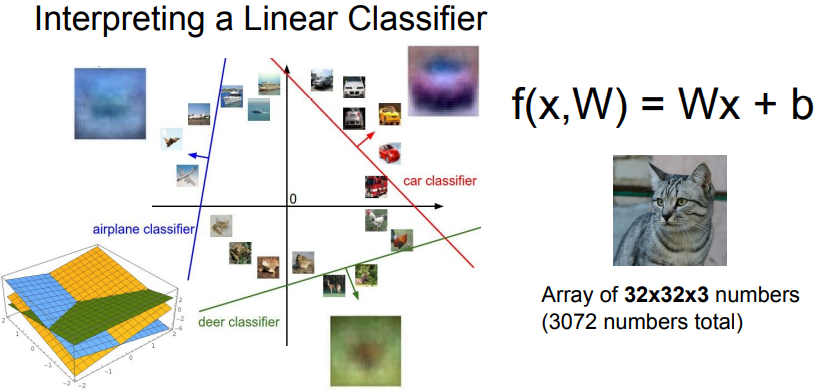
- Linear classifier는 각각의 Class를 구분 하는 Decision Boundary 역할을 함.
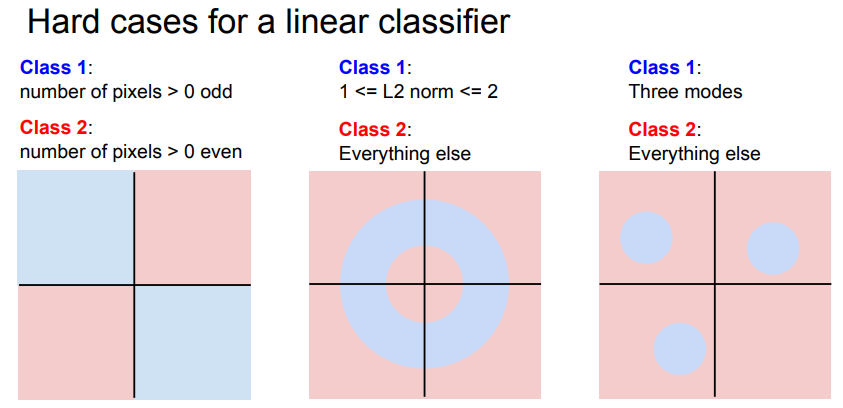
- 하지만 복잡한 Image를 판별하기 위한 Linear Classifier는 한계가 있음.
- Parity Problem (반전성 문제): 1,3 사분면 (홀수) 2,4 사분면 (짝수)를 단순히 선하나로 분류할 수 없음.
- Multimodel Problem : 한 Class가 다양한 공간에 분포하는 경우 Linear classifier로 해결하기 어려움.
Stanford University Youtube CS231n_Lecture2
댓글남기기