CS231n_Lecture 1
Introduction to Convolutional Neural Networks for Visual Recognition
Introduction
- 최근 현대 사회는 다양한 센서들로 부터 데이터를 수집하고 있음.
- 특히 핸드폰 등의 모바일 기기로 부터 다양한 Image데이터가 수집되고 있음.
- Vision 인식은 다양한 분야에서 활용 되고 있음.
![[Computer Vision 활용분야]](../../images/2022-05-08-CS231n_Chapter1/Untitled.png)
[Computer Vision 활용분야]
![[ Computer Vision 관련 Stanford University 강의 ]](../../images/2022-05-08-CS231n_Chapter1/Untitled%201.png)
[ Computer Vision 관련 Stanford University 강의 ]
Today’s agenda
1) A brief history of computer vision
2) CS231n Overview
1) A brief history of computer vision
- 5억 4천만년전 지구상의 생물들은 물체를 볼 수 있는 눈이 없었음.
- 화석 연구에 의하면 생물이 급격히 증가하는 시대가 있었고 그 이유는 생물이 볼 수 있게 되면서 부터임.
- 본다는 것은 생물 뿐만 아니라 사람에게도 중요한 감각임.
- 사람들은 보는것에 대해 연구하고 기계적 제작을 시작함.
- 현대에 카메라는 가장 흔한 센서 중 하나
![[초기 카메라의 모습]](../../images/2022-05-08-CS231n_Chapter1/Untitled%202.png)
[초기 카메라의 모습]
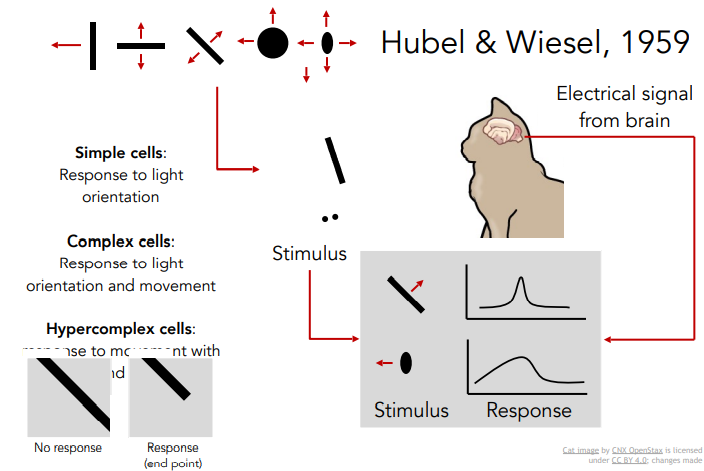
- 생물학자들 중 1950년대 휴벨과 위즐은 고양이 뇌 뒤에 전극을 꽂고 어떤 자극이 뉴런을 흥분하게 하는지 지켜봄.
- 이 연구에서 시각 처리가 처음에는 단순한 구조로 시작하고 점차 복잡해진다는 것을 발견함.
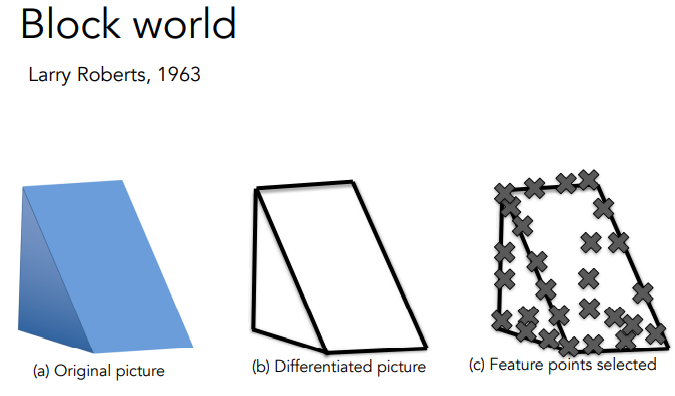
- 1960년대 초 래리 로버트는 세상을 간단한 기하 도형으로 단순화 하는 연구를 함.
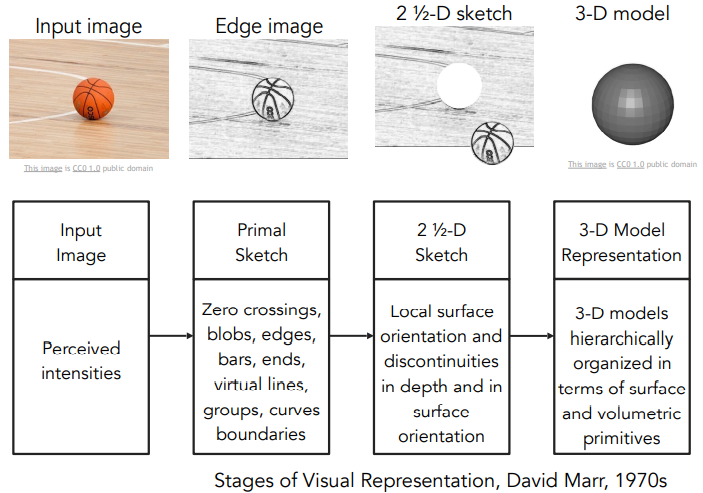
- David Marr는 1970년대 후반에 컴퓨터 비전의 방향에 대해서 다루었음.
- Input Image의 초기 스케치에서는 경계(edge)를 표현하고, 그 다음 표면과 깊이, 레이어 등을 불연속성으로 만듬.
- 그 다음 앞선 것들을 합쳐서 3차원 모델을 만듬.
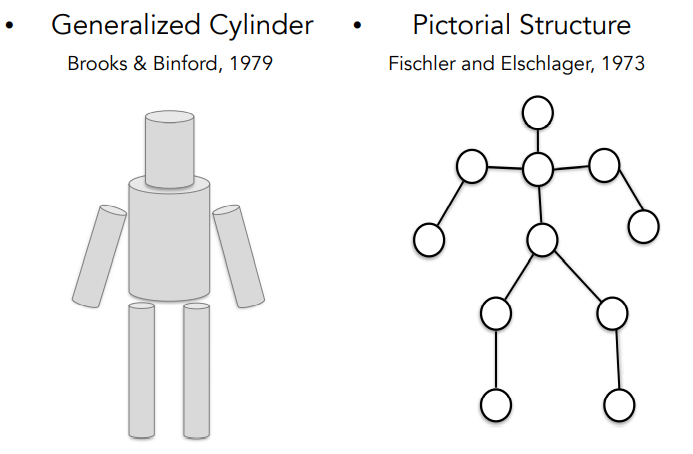
- 1970년대에 모든 물체가 단순한 기하학적 초기값 으로 표현될 수 있다는 아이디어가 제안됨.
- Generalized cylinder : 사람이 실린더 모양으로 표현될 수 있음.
- Pictorial structure : 주요 부위와 관절로 표현
- 1960~ 1980년대까지 Computer Vision에 대한 많은 노력이 있었지만 몇 가지 사물에만 적용이 가능했음.
- 한번에 인식하는 것이 어려웠기에 Image를 Segmentation (분할) 하는 방법에 대한 연구가 진행됨.
- Image의 각 픽셀을 의미 있는 방향으로 군집화 하여 각 분할된 픽셀이 무엇인지는 인식하지 못하더라도, 서로 다른 픽셀을 가려낼 수는 있었음. (Jitendra Malik & Jianbo Shi, 그래프 이론 알고리즘 사용)

- Face Detection 분야에서는 Image Segmentation 관련 연구 중 큰 진전이 있었음
- 1999년 ~2000년에 머신러닝 기법, 확률적 머신러닝 기법이 연구 성과를 내기 시작함.
- 서포트 벡터 머신, 부스팅 등 신경망 알고리즘의 첫번째 연구성과들도 주목을 받음.
- 특히 Adaboost를 활용한 Viola & Jones의 Face Detection은 실시간 Detection이 가능하여 많은 주목을 받음.
- 이 논문이 발표된지 5년만에 후지필름은 실시간 Face Detection이 가능한 디지털 카메라를 출시함.

- 1990년대 후반부터 2010년도까지 Feature 기반 Object Recognition이 주목을 받음.
- 카메라의 각도나 빛에 따라 객체의 모양이 변할 수 있지만 불변한 객체의 특징을 발견해서 다른 객체에 매칭시키는 David Lowe의 SIFT feature가 가장 유명함.

- 60~80년대를 거쳐 2000년대에 이르는 동안 인터넷과 디지털 카메라의 성장으로 이미지의 품질이 향상되었음.
- 2000년대 초반 물체 인식이 얼마나 잘 되는지 측정할 수 있는 방법 들이 고안됨.
- Pascal Visual Object Challenge는 20개의 Object Class로 되어 있고, 수천에서 수만장의 이미지로 이루어져 있음.
- 머신러닝에 기반한 모든 모델은 과적합(Overfitting) 되기 쉬었음.

- Visual Data는 매우 복잡하고 충분한 데이터가 없었으며, 과적합 때문에 일반화 하기가 어려웠음.
- 세상의 모든 물체를 인식하고, 머신러닝의 과적합을 극복하기 위해 Imagenet 프로젝트가 시작됨.
- Imagenet : 15만장의 이미지와 22만가지의 카테고리를 가진 데이터 셋

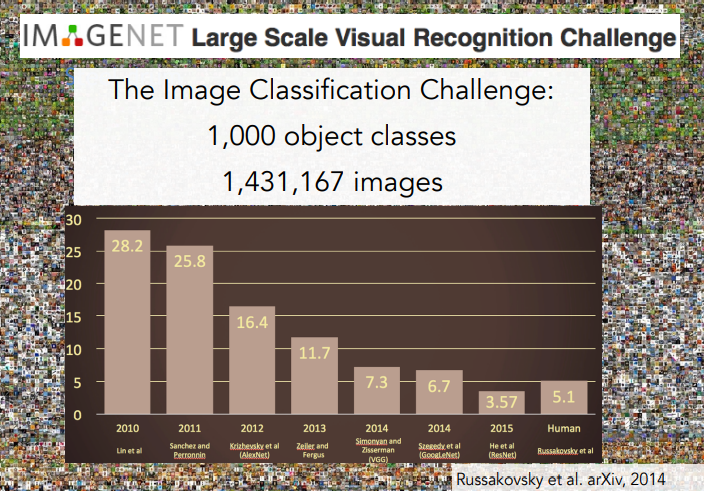
- 2009년 Imagenet팀은 국제 챌린지를 열었고, 140만장의 이미지와 1천개의 클래스 데이터를 활용하여 Computer Vision 알고리즘들을 테스트 하기 시작함.
- ILSVRC (Imagenet Large Scale Visual Recognition Test)
- 만약 알고리즘이 다섯개의 레이블을 출력할 수 있고, 그 다섯개의 레이블이 사진에 있다면 성공.

- 2010년부터 15년까지의 결과를 보면, 에러율이 지속적으로 낮아져서 2012년에는 사람과 비슷한 수준까지 에러율이 낮아짐.
- 2012년에는 전년보다 거의 10%의 에러율이 줄어 들었는데, 해당 년도에 우승 알고리즘은 CNN(Convolution Neural Network)였음.
2) CS231n overview
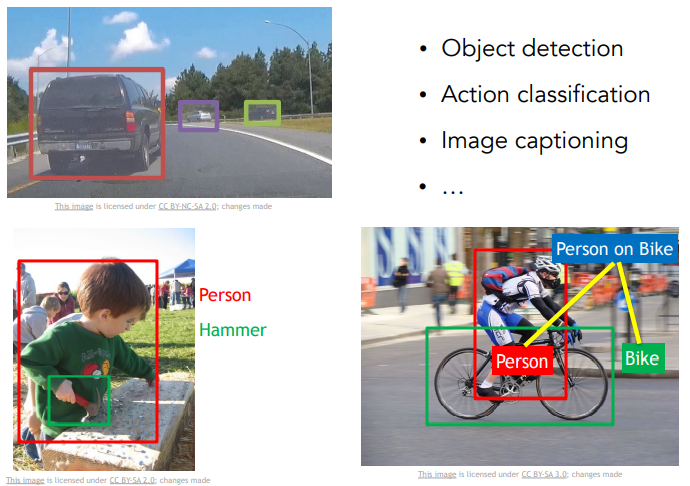
- CS231n 강의 에서는 Visual Recognition분야의 가장 중요한 문제 중 하나인 Image Classification (이미지분류)에 초점을 맞춤.

- Visual Recognition은 Object Detection(물체탐지), Image Captioning과 같은 Image classification과 연관된 경우가 많음.
- Image Captioning : 이미지가 주어지면 해당 이미지를 설명하는 자연어를 생성하는 것.
- Object recognition이 큰 발전을 이룬 것은 CNN(Convolution Neural Network)이 도입된 이후임.
- CNN은 Convnet 이라고도 불림.
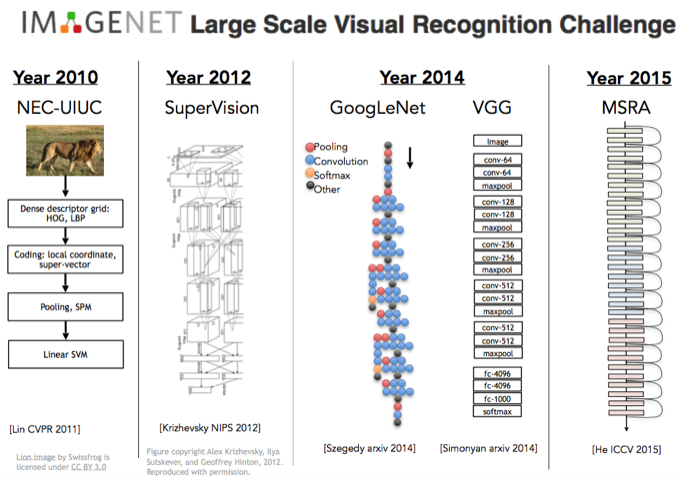
- 2012년 Imagenet 우승 알고리즘인 Krizhevsky의 CNN은 7개의 레이어를 사용. (Alexnet, Super Vision)
- 2015년 구글넷, 옥스포드의 VGG는 19레이어를 사용했고, 마이크로소프트의 Residual Network는 152개의 레이어를 사용함.
- 200개 이상의 레이어를 쌓으면 성능이 더 좋아지지만 GPU 메모리가 부족했음.
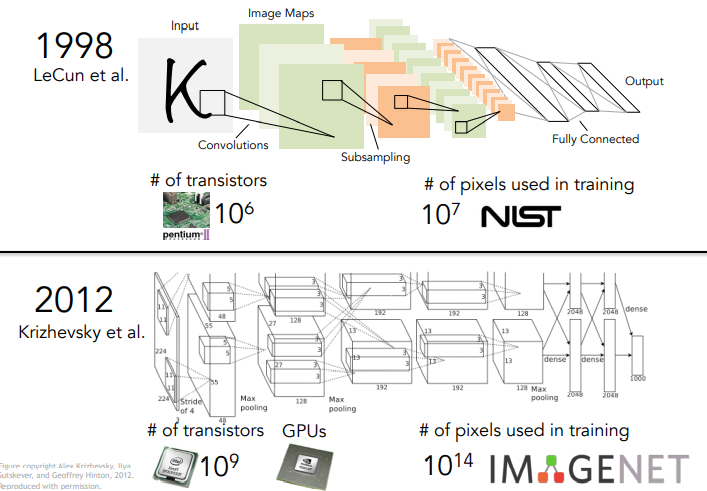
- CNN은 하루아침에 발명된 것이 아님.
- 1990년대 LeCun이 숫자인식을 위한 신경망을 만들었고 이를 이용하여 수표나 우체국의 주소를 자동으로 인식하려고 했음.
- 해당 알고리즘을 보면 Alexnet과 유사함.
- 90년대부터 연구되어온 CNN이 컴퓨팅 능력의 발전으로 최근에 많이 사용하게 되었음.
- GPU(Graphical Processing Unit)가 등장함으로써 슈퍼 병렬처리가 가능하고 이를통해 계산이 많이 필요한 CNN이 빠르게 발전할 수 있었음.
- 또한 90년대에는 레이블된 데이터가 없었던 반면, Pascal이나 Imagenet과 같은 방대하고 고품질의 레이블된 데이터가 만들어지면서 CNN 발전에 기여함.
- Computer Vision 분야는 사람처럼 보는 기계를 만드는 일을 하고 있음.
- Image 전체를 레이블하기보다 픽셀이 뭘 하고 있는지, 뭘 의미 하는지, 이미지의 모든 픽셀을 이해하고자 함.
- Stanford Vision Lab의 Johnson의 연구를 예로 들면, Visualgenome 데이터셋으로 복잡한 사항을 찾아 이미지에 단지 박스를 그리는 것이 아닌 의미적으로 연관된 큰 그래프로 이미지를 설명함.
![[왼쪽 - 단순 이미지 분류, 오른쪽- Visualgenome]](../../images/2022-05-08-CS231n_Chapter1/Untitled%2019.png)
[왼쪽 - 단순 이미지 분류, 오른쪽- Visualgenome]
- Fei-Fei의 대학원 시절 연구에서는 지나가는 사람의 길을 막고 0.5초 동안 이미지를 보여주고 해당 이미지에 대한 설명을 쓰게 했음.
- Computer Vision은 지난 몇 년간의 엄청 난 진보에도 불구하고 사람 수준에 도달 하려면 갈 길이 멈.

- Andrej Karpathy의 블로그에서 가져온 이미지를 보면 오바마의 장난을 뒤에 있는 사람들이 이해 하고 웃고 있음.
- Computer Vision이 이런 깊은 이해를 하기에는 갈길이 멀고, 아직 많은 문제가 해결 되어야 함.

- Computer Vision은 유용한 기술이며, 모든 분야에서 세상을 더 좋은 곳으로 만들어 줄 것임.
- CS231n에서는 더 깊이 파고들어 이 알고리즘이 어떻게 동작하는지에 대해 알아볼 것임.

댓글남기기